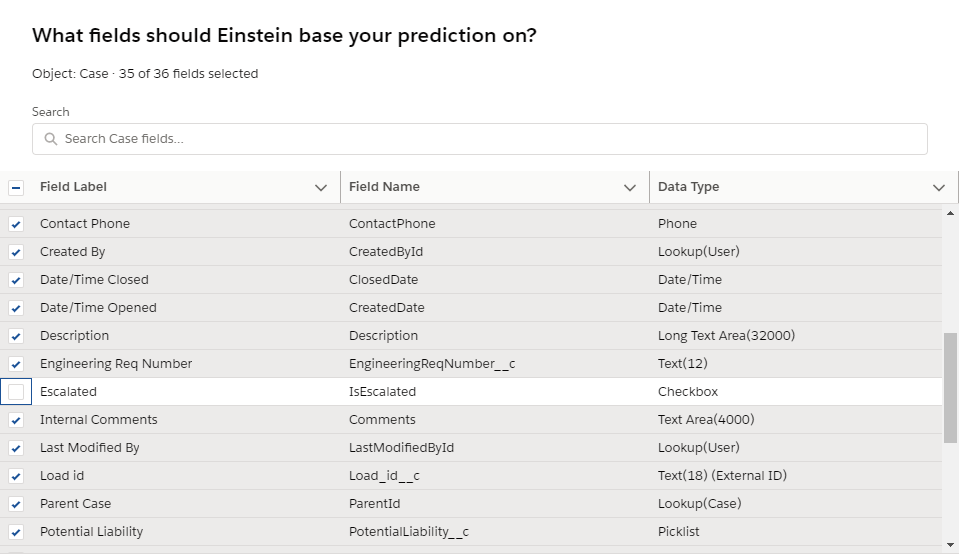
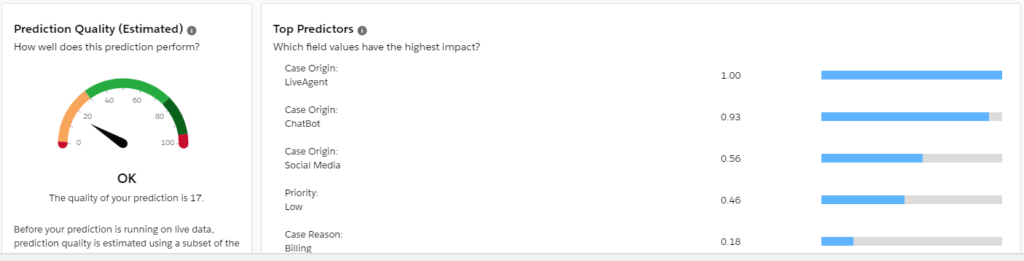
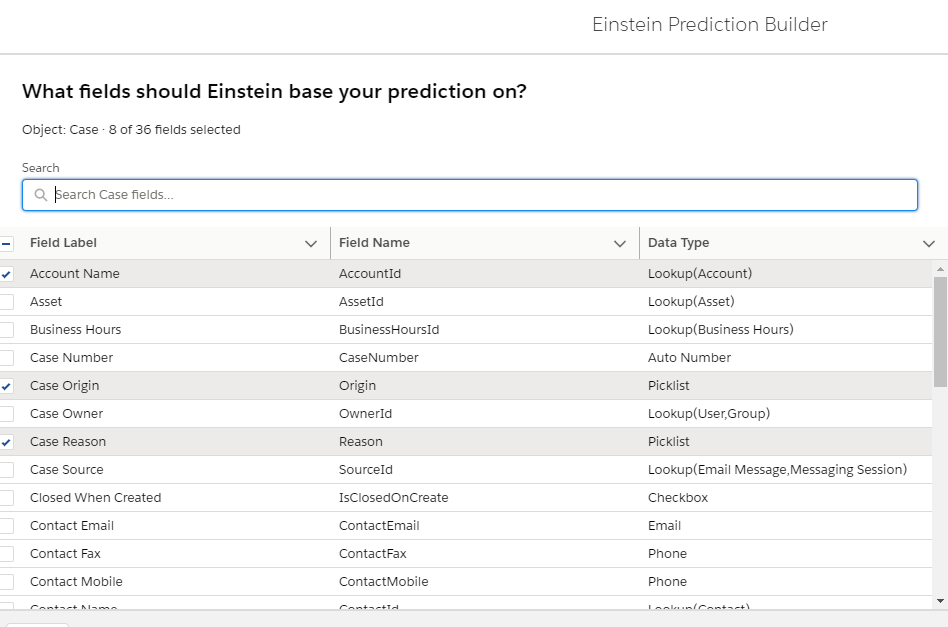
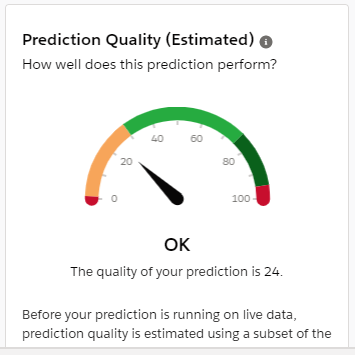
In my last blog on Einstein Prediction Builder, we were able to improve our prediction score by choosing the right fields for doing the prediction. Link to last blog – Einstein Prediction Builder : Improving Predictions through choice of fields
In this blog, we will understand why data quality is important for improving prediction results.
Imagine an astrologer predicting your future but doesn’t have your date of birth . Imagine a store predicting the sale in month’s to come, but they count the store and customer’s receipt of bills (i.e. double counting the sale proceeds).
This is a similar situation that we might encounter in our data. We are now going to talk through steps to improve data quality and thus improve our prediction.
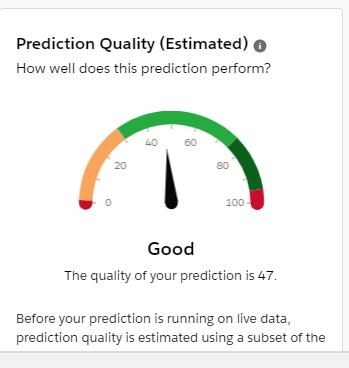
Just a quick recap, we achieved a score of 47 in the previous module.
STEP 1 : Remove the Duplicates
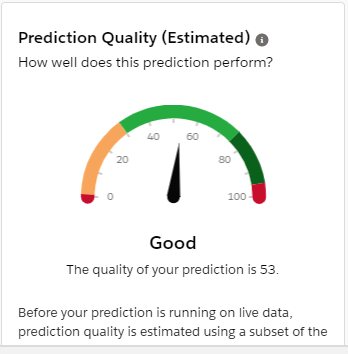
When we prepare the example set, it is important to cleanse the data to remove duplicates. Salesforce Duplicate Rules or products from AppExchange can help in cleaning data and removing the duplicates. Post removing the duplicates, it is important to re-evaluate the score. In our case, the score increased to 53.
STEP 2 : Validate Data in the example set
It is important to ensure that our example set has valid data. Try to give meaning to the data, by ensuring the fields are populated with proper and meaningful values.
Avoid values like etc. , any other reason, none of the above. Such values can result in low scores especially if they appear on large number of records.
Check if the data is correct and fix the data if there is an issue. This however requires involvement from business users to help in fixing the data and converting it into a meaningful information.
After completing the above, the score of my prediction became 85.
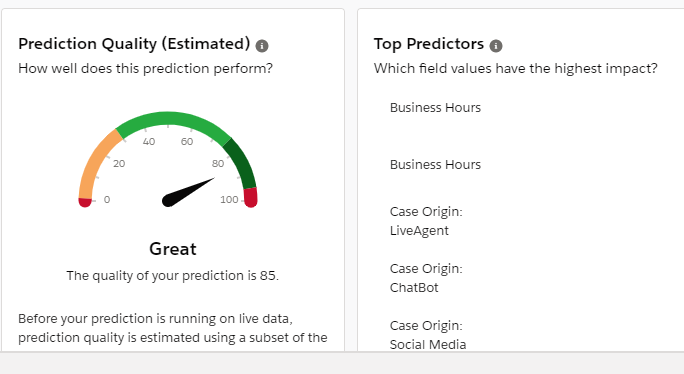
So with some basics checks, we moved our score from Good to Great.
It is important to note that it was not just improving the data quality that moved the score, it was series of steps that helped in reaching this mark. To reiterate it is
- Removing Hindsight Bias.
- Removing fields which are majorly blank (and will not have too much data in future).
- Removing fields which has no impact.
- Removing the Duplicate data.
- Validating the data.
We will next talk about the Einstein Prediction Builder Component (provided by Salesforce) in my next blog.